ZeroCopy
ZeroCopy,或者叫零拷贝,是Linux里面的一个技术,支持零拷贝的系统调用是sendFile/mmap;这里说的零拷贝并不是真的一次都不需要拷贝,而是,避免了从内核态到用户态,和从用户态到内核态的无意义拷贝;Java中对零拷贝的支持,主要是NIO里面的FileChannel.transforTo()/FileChannel.transforFrom()/MappedByteBuffer;
近年来大火的Kafka,它的高效读写数据部分,也使用到了零拷贝;我们先看个kafka对零拷贝的使用的一个整体情况,见下图:
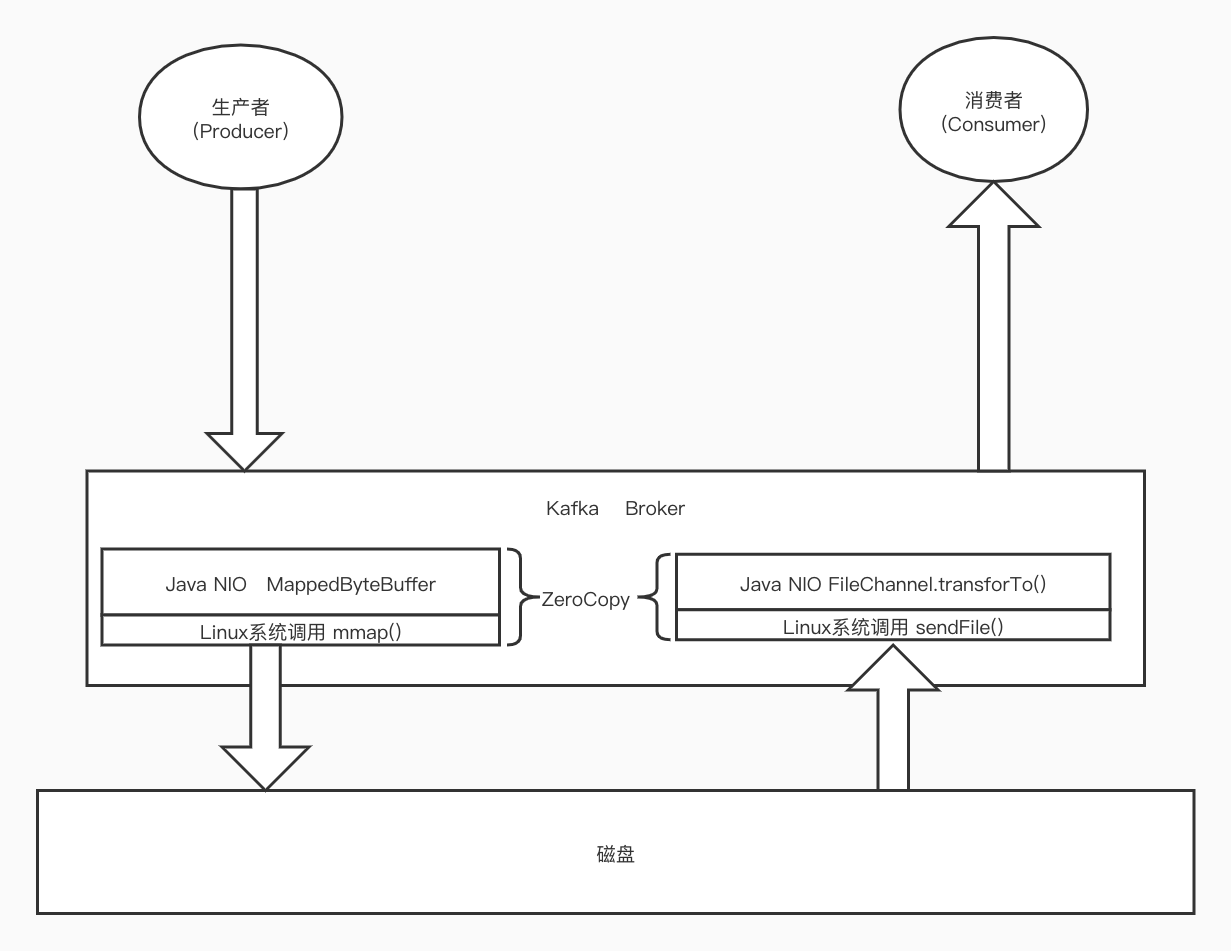
下面,我们详细介绍相关的情况;
DMA
DMA出现之前,各种数据传输工作都需要CPU,特别浪费。但是,实际上,这些数据传输工作用不到多少CPU核新的“计算”功能。另一方面,CPU的运转速度也比I/O操作要快很多,所以,导致CPU资源又被IO阻塞,又是阻塞在了没有太大意义的事上。
后来,抱着“希望能够给CPU“减负”的想法,工程师们就在主板上加上了DMAC这样一个协处理器芯片,通过这个芯片,CPU只需要告诉DMAC,我们要传输什么数据,从哪里来,到哪里去,就可以放心离开了。后续的实际数据传输工作,都会由DMAC来完成。随着现代计算机各种外设硬件越来越多,光一个通用的DMAC芯片不够了,我们在各个外设上都加上了DMAC芯片,这样,就使得CPU很少再需要关注数据传输的工作了。
在我们实际的系统开发过程中,利用好DMA的数据传输机制,也可以大幅提升I/O的吞吐率。最典型的例子就是Kafka。
读取数据并发送到网络
普通的方式和使用零拷贝技术的对比
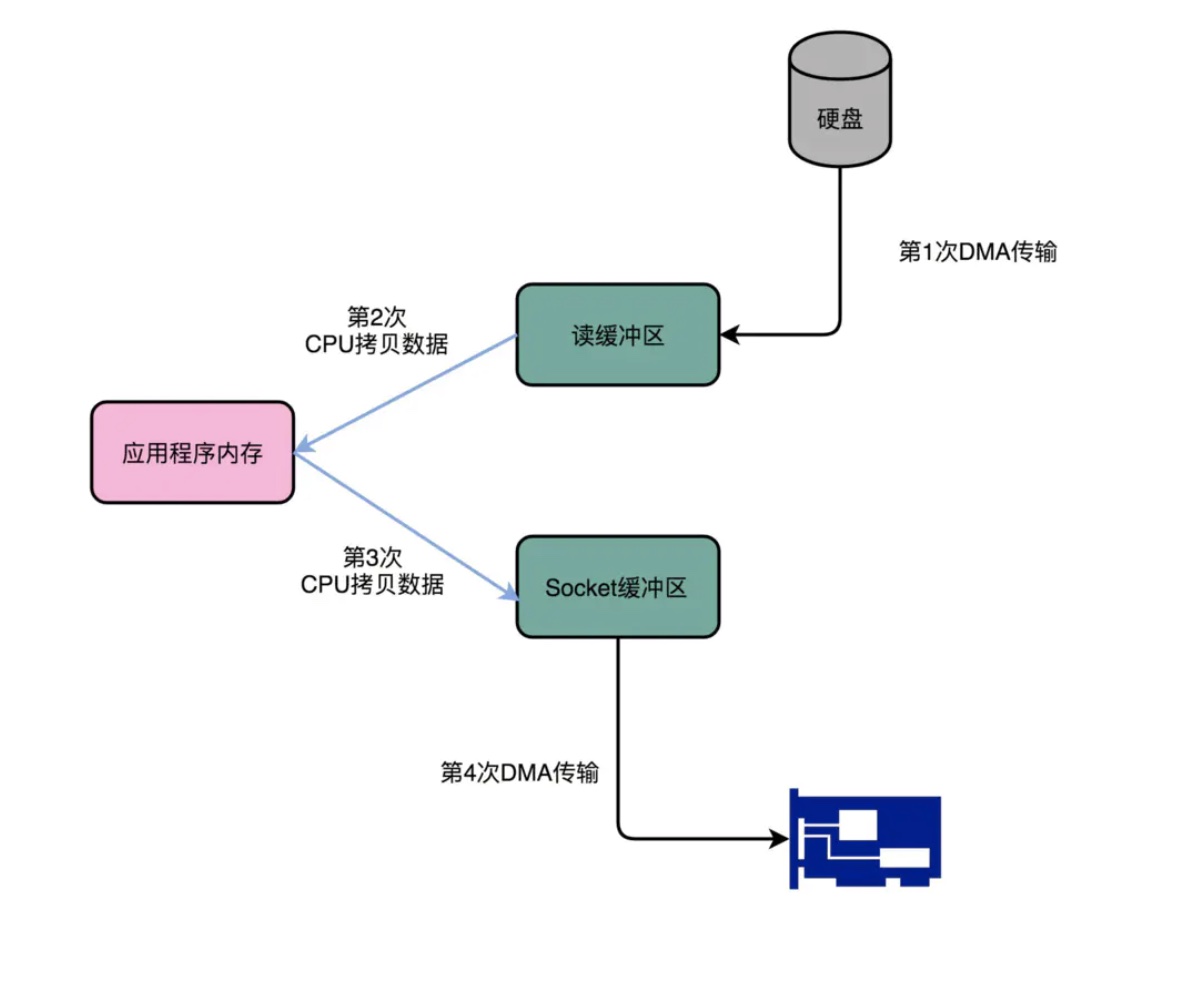
首先看下普通的读取数据并发送到网络的操作,实际底层执行时对应的动作:
例如,我们的实现是 读取文件,再用socket发送出去,那么,我们使用传统方式实现时,大致要经过如下过程:
先读取、再发送,实际经过1~4四次copy。
1、第一次:将磁盘文件,读取到操作系统的内核缓冲区(DMA);
2、第二次:将内核缓冲区的数据,copy到application应用程序的buffer(用户空间【内存】)(CPU);
3、第三步:将application应用程序buffer中的数据,copy到socket网络发送缓冲区(内核空间【内存】)(CPU);
4、第四次:将socket buffer的数据,copy到网卡,由网卡进行网络传输(DMA)。
然后,我们下面再看下使用零拷贝(sendFile/ Java:FileChannel.transforTo() )之后的流程:

我们会发现,使用了零拷贝之后,不再需要CPU拷贝了,原来的CPU拷贝的流程都省去了。
使用了零拷贝方法后,传输同样数据的时间,可以缩减为原来的1/3,也就是提升了3倍的吞吐率。
接收数据并写入到磁盘
这里我们就不再详细介绍普通的接收数据写入到磁盘的方式了,直接介绍下mmap的原理:
mmap (** Memory Mapped Files** )是一种内存映射技术,可以将文件或对象映射到进程的内存地址空间,使得进程就像操作内存一样实现了“直接”对文件的高效读写。本质上来讲, mmap 实现的是内核缓冲区与用户进程的地址空间的映射,也就是说用户进程通过操作自己的逻辑虚拟地址就可以实现操作内核空间缓冲区,这样就不用再因为内核空间和用户空间相互隔离而需要将数据在内核缓冲区和用户进程所在内存之间来回拷贝。
** 通过mmap,进程可以像读写硬盘一样读写内存(当然是虚拟内存),使用这种方式可以获取很大的I/O提升,省去了用户空间到内核空间复制的开销。**
** mmap也有一个很明显的缺陷——不可靠,写到mmap中的数据并没有被真正的写到硬盘,操作系统会在程序主动调用flush的时候才把数据真正的写到硬盘。Kafka提供了一个参数——producer.type来控制是不是主动flush;如果Kafka写入到mmap之后就立即flush然后再返回Producer叫同步(sync);写入mmap之后立即返回Producer不调用flush叫异步(async)。**
当然,Kafka之所以成为了实时数据传输管道的标准解决方案,或者说kafka的快速,也还与它使用磁盘的顺序读写有关;
顺序读写
我们简单说下是否顺序读写的对比:
磁盘顺序读或写的速度400M/s,能够发挥磁盘最大的速度。随机读写,磁盘速度慢的时候可能才十几到几百K/s。
kafka将来自Producer的数据,顺序追加在partition,partition就是一个文件,以此实现顺序写入。Consumer从broker读取数据时,因为自带了偏移量,接着上次读取的位置继续读,以此实现顺序读。顺序读写,也是kafka利用磁盘特性的一个重要方面;
为什么顺序读写更快呢?因为,顺序读写,可是充分利用CPU的预读,以及 可以避免写入放大效应;当然,还有就是一些寻址上的简化了。
read more
Comments